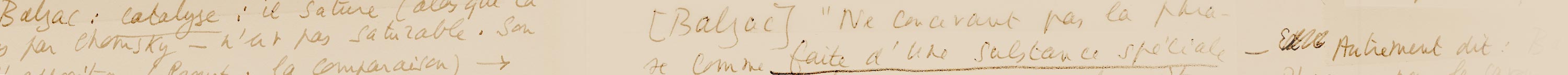

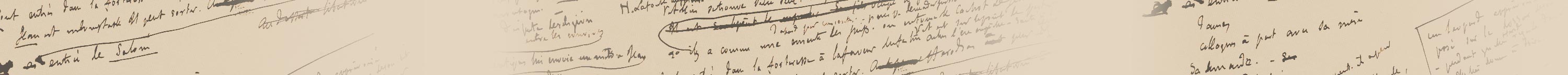




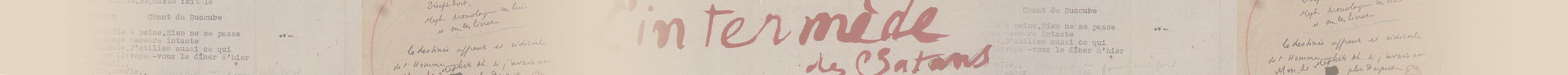
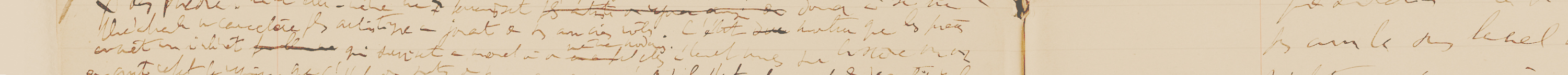




06/11/2008
L’objectif d’OPTIMA (Outils Pour le Traitement de l’Information dans les MAnuscrits modernes) est de créer les outils théoriques et techniques permettant de lever les obstacles matériels et intellectuels qui s’opposent encore à une véritable valorisation des grands corpus de manuscrits modernes qui, pour la plupart, restent inexplorés et à l’état de documents illisibles dans nos grandes bibliothèques européennes. L’outil numérique en a les moyens s’il associe ses ressources à celles d’une méthodologie d’approche du manuscrit moderne, la génétique des textes. Il s’agit de convertir une masse opaque de manuscrits autographes – inédits parce qu’illisibles – en un « avant-texte » transcrit et classé permettant d’interpréter les processus qui ont produit le texte. Le projet est de faire sauter les verrous qui interdisent l’accès à cet énorme gisement de savoirs et de modèles cognitifs que contiennent les « brouillons » de la culture moderne. Le projet s’inscrit donc dans le prolongement des méthodologies en « génétique textuelle » développées à l’Institut des Textes et Manuscrits Modernes (ITEM). Le but est de rendre possible une édition hypertextuelle érudite des fonds, mais en privilégiant d’abord la conception et la mise au point des outils numériques fondamentaux qui, à ce jour, font cruellement défaut. L’expérience porte sur plusieurs « grands corpus », comportant des modèles d’écritures diversifiés : à programmation scénarique (Flaubert), à structures séquentielles complexes (Proust, Valéry), à forme combinatoire (« fichier » Braudel). Le projet s’appuie sur l’excellence et la complémentarité des 5 partenaires qui en constituent le dispositif : 2 équipes sur corpus (l’ITEM et la MSH), 1′ équipe d’archivistes (BnF) et 2 équipes d’informaticiens (le LITIS et le LIPN).
Cette journée d’étude du jeudi 6 novembre 2008, consacrée à un bilan détaillé à mi-parcours du projet OPTIMA, aura lieu dans la Salle des commissions de la BnF, site Richelieu, 58, rue Richelieu, 75002.
Accueil des participants à 9h45
10h-10h45
Présentation générale du projet et du bilan à mi-parcours par Pierre-Marc de Biasi, directeur de l’ITEM et responsable du projet
10h45-11h15
Présentation du programme de numérisation par la BnF
11h15-11h30
Pause
11h30-12h45
Présentation du corpus « Fernand Braudel » par Paola Arzenati (Maison des Sciences de l’Homme) et du corpus « Marcel Proust » par Nathalie Mauriac et Pyra Wise (équipe « Proust » de l’ITEM)
Présentation de l’outil de transcription « TranScript » par Le Laboratoire d’Informatique, de Traitement de l’Information et des Systèmes, le LITIS, (Thierry Paquet et Thomas Palfray)
Discussion
12h45-14h30
Déjeuner
14h30-14h50
Présentation du traitement codicologique par Serge Linkès (équipe Techniques et Pratiques de l’écrit de l’ITEM)
14h50-16h05
Présentation des spécificités du corpus « Gustave Flaubert » par Pierre-Marc de Biasi, Sylvie Giraud, Déborah Boltz (équipe « Flaubert ») et du corpus « Paul Valéry » par Janeta Maspero (équipe « Valéry » de l’ITEM)
Présentation des travaux fournis et prévus par Le Laboratoire d’Informatique de Paris-Nord (LIPN) (Christophe Fouqueré et Lionel Falempe)
Discussion
16h05-16h20
Pause
16h20-17h
Table ronde générale sur les spécificités et les résultats attendus du projet OPTIMA