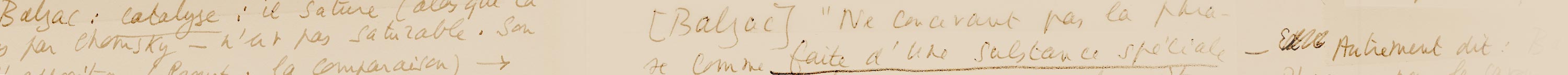








Sommaire
- Historique du projet et conception de la base
- Choix du logiciel et du mode relationnel
- Structure de la base, relations entre les fichiers
- Le traitement des corpus : manuscrits de Montesquieu, Stendhal, Duchamp et Condorcet
- Autres corpus représentés et limites actuelles de l’application
- Notes de bas de page
L’approche génétique des manuscrits requiert un travail important d’observation et de description, préalable au classement des matériaux constituant le dossier, à la transcription des manuscrits et à l’interprétation des processus d’écriture. En effet, s’agissant de création littéraire, l’expérience montre que l’objet intellectuel et l’objet matériel sont indissociables1, l’opération de déchiffrement et de mise en séquence des phases de rédaction impliquant de constants allers et retours entre le lisible (ou l’illisible) – ce qui est écrit, ou du moins tracé – et les indices matériels – comment c’est inscrit, par quelle main, avec quel instrument d’écriture, sur quels supports, affectés de quels marquages, signes de renvois, numérotations, etc.
L’ITEM s’est préoccupé de longue date d’affiner la méthodologie descriptive appliquée aux manuscrits pour l’adapter aux spécificités des corpus modernes, concernant notamment le relevé des caractéristiques matérielles2. L’informatisation des données ainsi recueillies systématiquement s’est avérée indispensable dès la fin des années quatre‑vingt. Un premier prototype de base de données consacrée à l’analyse matérielle, qui fut présenté lors d’une rencontre internationale organisée à Paris en 19933, permettait surtout d’archiver et de rendre accessibles les descriptions de papiers et les reproductions de filigranes déjà existantes. Toutefois la structure de cette base de données, équivalente à celle d’un répertoire de filigranes adaptée à la consultation électronique, procédant par échantillons ponctuels de manuscrits autographes datés, ne répondait pas aux besoins de recherches codicologiques et génétiques qui seraient menées conjointement sur un même corpus, lesquelles nécessitent un relevé exhaustif des occurrences4. Fallait‑il se contenter de développer séparément des outils de travail mettant à profit l’apport de la technologie informatique pour améliorer et rentabiliser la collecte des données codicologiques d’une part, et pour normaliser les modèles de transcription génétique et mettre au point diverses formes d’édition électronique des manuscrits d’autre part ? Grâce à un travail d’équipe, nous avons tenté de relever le défi méthodologique en imaginant un instrument de travail original.
Historique du projet et conception de la base MUSE
L’application MUSE, opérationnelle depuis 2000, constitue l’aboutissement de plusieurs années de recherche menées en collaboration sur le terrain. La partie codicologique reprend en les perfectionnant les éléments d’abord expérimentés dans Profil, la première base de données codicologique de l’ITEM. L’apport de celle‑ci résidait principalement dans la mise en relation d’images de filigranes issues du traitement numérique de bêtaradiographies5 avec des données descriptives détaillées. Les informations fournies pour chaque type de papier6 filigrané concernaient non seulement la description du filigrane, la localisation du support et sa date d’utilisation, mais aussi un descriptif plus complet des autres caractéristiques du papier7. Le choix de ces critères avait été confirmé par les travaux de l’Association internationale des Historiens du Papier (IPH) dont une première proposition pour une norme internationale devait paraître en 19968. Toutefois, dans la mesure où Profil était conçue comme outil de référence pour une consultation publique, les occurrences faisaient l’objet d’une simple liste, et non d’une étude détaillée. Prototype d’un répertoire plus étendu qui n’a jamais vu le jour, Profil comportait cinq cents types de papiers, provenant de manuscrits littéraires datant du milieu du XVIIe au milieu du XXe siècle, tous filigranés, ainsi qu’un répertoire documenté des papetiers9.
Plusieurs initiatives comparables ont vu le jour à la fin des années quatre‑vingt‑dix. Comme la nôtre, il s’agissait surtout de bases filigranologiques, certaines reprenant la perspective historique large des répertoires de filigranes anciens, dans lesquels les documents traités sont uniquement indexés en tant que source de datation ou de localisation des filigranes reproduits, d’autres s’attachant à l’analyse détaillée voire exhaustive d’un unique corpus littéraire ou philosophique10. Aucune à notre connaissance ne recherchait une vocation généraliste portant sur plusieurs corpus tout en fournissant une identification précise des données textuelles figurant sur chaque occurrence analysée, comme le proposait la base Profil.
Cependant l’utilisation de cet outil pour la description codicologique des corpus s’avérait limitée : que faire des papiers non filigranés, abondants au début du XIXe siècle et au cours du XXe, comment traiter les feuillets incomplets et les fragments, signaler les feuillets initialement solidaires ayant subi telle manipulation ou altération au cours de la genèse ? Comment coordonner les données issues de l’analyse matérielle et les observations complémentaires concernant l’agencement de la surface graphique ? C’est à la faveur d’un programme collectif du CNRS intitulé « Archives de la création » qu’un nouveau projet a pu prendre forme, se donnant pour objectif de concevoir une base de données relationnelle permettant d’aborder l’objet manuscrit par divers angles complémentaires, même si l’analyse matérielle en demeure l’axe principal. Outre la souplesse de manipulation souhaitée pour en faire un véritable instrument de recherche, il s’agissait d’intégrer la description matérielle proprement dite (types de supports et instruments d’écriture, inventaire des occurrences) et la collecte de données concernant l’identification des écritures, le classement et l’utilisation des feuillets, les caractéristiques des ratures et de la mise en page, afin de faciliter le repérage des différentes campagnes d’écriture.
Avant de présenter la base de données MUSE d’un point de vue technique, il paraît nécessaire de la distinguer des autres bases de données qui se développent actuellement dans le monde littéraire. En effet, dans ce domaine tout comme dans les sciences « dures », les chercheurs se sont rapidement persuadés que l’informatique pouvait devenir un allié de la recherche. Malgré la relative méfiance qui semble persister entre la littérature et l’informatique, on voit régulièrement paraître de nouvelles expériences ; les traitements de texte d’abord, puis d’hypertexte, sont devenus dorénavant les instruments permettant de repousser les limites du texte littéraire en tant qu’objet d’investigation. Outre les progiciels, les bases de données semblent être l’application informatique la plus utilisée par les chercheurs littéraires. Il suffit d’une recherche sur Internet pour avoir une idée du nombre impressionnant de bases de données élaborées dans ce domaine. Les applications pour la recherche sont nombreuses : bibliographique, lexicologique, de critique textuelle, linguistique, lexicographique, stylistique… et même plus originales comme la base de données « Viatique » du Centre de Recherche sur la Littérature des Voyages de l’université Paris IV11.
MUSE n’est‑elle dès lors qu’une base de données parmi d’autres ?
Nous espérons démontrer ici que MUSE est bien plus qu’une simple base de données d’information littéraire. La plupart des bases développées en recherche littéraire sont en effet avant tout des bases informatives. Elles sont une interface de consultation rapide permettant de retrouver par le biais d’une requête plus ou moins complexe une information précise parmi la multitude d’informations contenues dans la base. La plupart du temps, le recours à cet outil devient nécessaire lorsque le nombre d’informations est trop grand pour permettre une consultation plus traditionnelle (fiches, répertoires…) ou lorsque l’on veut permettre à un plus grand nombre de chercheurs de consulter ces informations. La mise en réseau des bibliothèques12 et surtout l’apparition d’Internet sont certainement les principales raisons de l’apparition des bases de données littéraires. MUSE suit un principe différent, puisque c’est une des rares bases qui a pour but de construire son objet d’étude : le manuscrit littéraire.
Construire un objet d’étude littéraire à partir d’une application informatique peut paraître paradoxal et même aberrant au premier abord. Pourtant, si comme toutes les bases MUSE est un outil de recherche, c’est aussi et avant tout un système heuristique permettant la gestion d’analyses des données codicologiques et génétiques et la formulation d’hypothèses. Ainsi la base, qui a été conçue dans un premier temps pour permettre une recherche comparative dans le domaine codicologique, s’avère utile pour toute étude nécessitant la comparaison de données empiriques, qu’elles soient d’ordre génétique ou critique.
Fig.1 Processus d’analyse des papiers

Contrairement aux répertoires informatisés qui transmettent des données d’emblée analysées selon les hypothèses des chercheurs, MUSE doit permettre de proposer des hypothèses à partir de la multitude des données collectées par le codicologue. En effet, c’est à partir du croisement des données concernant chaque feuillet que pourront être identifiés les différents types de papier, les différentes interventions scripturales. La définition d’un type de papier, et de ses interactions avec les opérations d’écriture, intervient donc au terme de la description codicologique exhaustive d’un ou plusieurs volume(s) manuscrit(s). Le manuscrit dans son ensemble, l’objet intellectuel et l’objet matériel, se trouvent donc au début et à la fin de cette chaîne de données. Au début, car il est l’objet concret soumis à l’observation, à l’analyse matérielle et graphique, et à la fin, car il est l’objet virtuel défini par l’hypothèse résultant du croisement des données.
Du point de vue de la méthode codicologique, l’utilisation de la base entraîne d’importantes conséquences. D’une part, le caractère systématique de la collecte informatisée impose une normalisation des critères descriptifs : nous avons ainsi réduit les options pour l’identification des couleurs du papier, distingué les données mesurables des évaluations qualitatives et séparé les zones de remarques. La capacité de calcul de l’ordinateur donne en outre accès à l’exploitation de données chiffrées, encourageant le recours aux instruments de mesure tels le micromètre et le perthomètre (les mesures d’épaisseur et de rugosité donnant lieu à des calculs automatiques de moyennes, par exemple). D’autre part, la base de données relationnelle autorise la visualisation comparative d’une quantité de données dépassant largement nos capacités de mémorisation, le stockage permettant une accumulation qui rend la base de plus en plus performante au fur et à mesure du traitement des corpus successifs (consultation des types de papiers déjà inventoriés13, des informations historiques sur les fabricants, sur les copistes, recoupements avec des occurrences relevées dans d’autres corpus, etc.).
Enfin, le réseau de relations entre les fichiers constitue un contexte multiple pour chaque groupe de données, et permet de mettre au jour des interactions insoupçonnées entre divers aspects de l’activité de l’écrivain telle qu’elle nous est restituée par le témoin manuscrit. Nous sommes ainsi passés d’une base de références – à l’instar des répertoires de filigranes – à un instrument de recherche permettant non seulement de collecter les données in situ, mais aussi de tester des hypothèses de classement. Examinés conjointement, les indices matériels et les divers états du matériau scriptural révèlent des façons de faire, des gestes, des usages inspirés par le projet créatif et qui, en retour, informent celui‑ci14. Cette notion d’usages des matériaux et des moyens graphiques au service de la création nous a paru déterminante, c’est pourquoi la base que nous présentons aujourd’hui comme un nouvel outil de travail fonctionnel pour les chercheurs (codicologues, généticiens, ou autres) étudiant des corpus du XVIIIe au XXe siècle s’intitule « MUSE » : Manuscrits, Usages des Supports et de l’Ecriture.
Choix du logiciel et du mode relationnel
Lorsque le chercheur littéraire souhaite aborder le monde informatique, il doit accepter d’adopter les stratégies en vigueur dans cet univers. Ainsi, tout bon informaticien sait qu’il est impossible d’élaborer une base de données sans passer par l’étape primordiale de la conception du système d’information. Ce système permet non seulement d’organiser les données (organisation des fichiers et des relations entre les fichiers), mais aussi d’envisager les aspects humains de la base de données : utilisateurs en amont et en aval, organisation de la saisie des données, maintenance, sauvegarde, conditions d’utilisation…
Ce système doit donc être élaboré en étroite collaboration par toutes les parties intéressées afin de tenir compte des besoins, des attentes et des contraintes de chacun. Dans le cas de MUSE, ce travail a été réalisé en présence d’utilisateurs potentiels étudiant des corpus de nature et d’époques différentes. L’organisation des données dans chaque fichier a également donné lieu à des débats afin de définir les termes descriptifs et critiques à utiliser, les automatismes permettant d’éviter les saisies rébarbatives… La même attention a été portée à la définition des relations entre les fichiers.
L’autre aspect de la mise en place du système d’information concerne le choix du logiciel permettant d’élaborer une base de données. Ce choix représente un enjeu considérable, c’est même l’un des éléments essentiels du cahier des charges. On en tient rarement compte au moment de se lancer dans une telle aventure… Pourtant, ce choix conditionnera la compatibilité, la pérennité, et l’évolution de la base de données. N’oublions pas que le but d’une base est avant tout de communiquer des données, même si son interface peut paraître moins conviviale que certaines interfaces Web très communes aujourd’hui. Notre choix a donc d’abord été conditionné par un souci de compatibilité entre plateformes PC et Macintosh. Cette base devait non seulement être compatible Mac et PC tout en étant utilisable sur n’importe quel système d’exploitation, elle devait également faciliter un échange dynamique des données.
Cette condition explique que nous ayons choisi d’utiliser un logiciel du commerce et non de développer une application à partir d’un langage de programmation. Les logiciels de bases de données compatibles Mac/PC étaient assez rares à l’époque de la gestation de MUSE ; nous avons opté pour le logiciel File Maker Pro qui semblait le plus adapté à notre projet puisque la société qui le proposait avait comme principal souci cette compatibilité – descendante et ascendante. De plus, le dynamisme de cette société laissait supposer que ce logiciel ne risquait pas de disparaître du jour au lendemain, comme c’est souvent le cas dans le monde informatique. Il faut également signaler que ce logiciel était accompagné d’un module permettant de créer des applications autonomes libres de droit à partir de la base de données réalisée, ce qui nous a permis de multiplier les versions de MUSE sur différents postes de travail.
Afin de mieux comprendre les besoins auxquels doit répondre la base, suivons pas à pas la démarche descriptive préalable à tout travail génétique15. En abordant un corpus manuscrit, qui a été constitué d’après le catalogue de l’institution de conservation ou à partir des travaux déjà existants, le ou la codicologue commence par inventorier les supports qui composent les différents volumes ou liasses : les ensembles, reliés ou non, constituent‑ils des séquences homogènes ou des recueils hétérogènes du point de vue matériel (cahiers, carnets ou feuilles volantes, formats in‑folio ou in‑quarto, qualité des papiers, modalités d’assemblage, etc.) ? De même on distinguera les documents autographes des interventions allographes, mains de copistes, secrétaires ou familiers de l’écrivain, et l’on relèvera d’éventuelles marques d’origine privée ou institutionnelle concernant le classement du corpus (foliotation, pagination, annotations marginales, feuillets intercalaires). Une seconde étape (voir fig. 1) consiste à repérer les différents types de papier utilisés : chaque feuillet est donc mesuré et décrit dans le détail, y compris, le cas échéant, son filigrane, afin de regrouper progressivement sur une même fiche toutes les occurrences d’un même type de papier, les occurrences douteuses pouvant rester en attente d’une identification ultérieure (types « indéterminés »). Quant aux aspects graphiques, chaque page écrite fait l’objet d’une analyse scripturale : couleur de l’encre, nature du ou des instrument(s) d’écriture, caractéristiques courantes ou exceptionnelles de la disposition spatiale, numérotation unique ou multiple. Dans un troisième temps, le chercheur recourt aux diverses sources qui lui permettront de mieux situer les phases de rédaction dans l’espace et le temps : sources biographiques et études littéraires d’une part, ouvrages sur l’histoire du papier et répertoires de filigranes d’autre part. C’est en procédant à une comparaison systématique des données codicologiques, scripturales et historiques que l’on peut obtenir une synthèse descriptive suffisamment complète (identification, répartition et modalités d’utilisation, classement) pour servir de base à l’analyse génétique proprement dite des manuscrits examinés16.
La base de travail doit donc permettre la collecte systématique, dans les divers fichiers réservés à chaque aspect du manuscrit (voir fig. 2), des données concernant les papiers, les filigranes et timbres secs qui les marquent, les scripteurs et les instruments d’écriture qu’ils emploient, les auteurs et les œuvres traitées, les volumes ou autres unités matérielles (« supports ») examinés et les feuillets qui les composent. Enfin chaque feuillet comprend nécessairement deux pages, écrites ou vierges, paginées ou non, se prêtant à l’analyse génétique des opérations d’écriture. L’enjeu d’une telle répartition des informations consiste à rationaliser la saisie mais aussi et surtout à permettre les recoupements entre divers fichiers en réponse à des requêtes multicritères.
Structure de la base, relations entre les fichiers
Fig. 2 : Interactions et relations entre les fichiers de MUSE

D’un point de vue logiciel, MUSE devait pouvoir gérer les intégrités référentielles entre les différents fichiers qui la composent, afin d’éviter tous risques de doublons ou d’erreurs d’attribution (une base de données qui se contenterait d’effectuer le tri de fiches ne pourrait en aucun cas être garante de la validité des recherches).
Ainsi la base de données que nous avons mise au point est répartie en plusieurs fichiers, chacun comportant un certain nombre de données spécifiques. Les relations établies entre les fichiers agissent principalement lorsque l’on ajoute ou supprime des enregistrements17. Elle est la garante de la validité des recoupements futurs... Le respect de ces règles nous garantit donc, par exemple, que chaque folio décrit ne sera associé qu’à un seul type de papier. Ainsi, lors d’une interrogation sur le type de papier vélin « Chambellan », MUSE fournira uniquement la liste des folios rédigés sur ce type de papier, en excluant les autres, puisque seules certaines des entrées du fichier « Occurrences » sont liées à la fiche unique donnant la description de ce type dans le fichier « Papier ». La multiplication des fichiers dans une base de données relationnelles permet, contrairement à ce que l’on pourrait croire, d’accroître la souplesse d’utilisation et surtout la rapidité du traitement des informations.
En effet, tous les fichiers étant liés entre eux et respectant l’intégrité référentielle (un seul enregistrement est lié à un autre enregistrement ou à plusieurs, selon la nécessité), nous pouvons créer pour les besoins de la saisie une fiche principale qui fera apparaître côte à côte différentes « tables » (listes totales ou partielles des rubriques figurant dans les fichiers liés) reliées, ce qui permettra d’enregistrer sur une seule fiche toutes les informations concernant une page.
Fig. 3 : Relation entre deux tables de la base MUSE

La figure 3 présente le type de relations qui est mis en œuvre dans la base de données MUSE. Les fiches « Papier » et « Timbre sec » sont reliées par le champ « Identifiant timbre sec » qu’elles ont en commun. Les informations concernant le timbre sec seront saisies une fois pour toutes dans le fichier « Timbre sec » et simplement rappelées lors de la saisie, dans la table « Papier », des informations concernant les caractéristiques du papier, parmi lesquelles figure ce timbre. La relation mise en œuvre dans ce cas est du type « 1 à ∞ » : en effet, théoriquement, chaque papier ne peut revêtir qu’un seul timbre de papetier, alors qu’un timbre, qui est une marque de fabricant, peut être apposé sur différents types de papier. En effet, à la différence du filigrane, le timbre sec est apposé après la fabrication du papier industriel. Il n’est donc pas un critère suffisant pour assurer l’identification du type de papier, mais il permet d’en repérer la provenance, indice qui peut s’avérer déterminant comme nous avons pu le constater lors de l’analyse de manuscrits stendhaliens. On retrouve dans le manuscrit de Lamiel, rédigé dans les derniers moments de la vie de Stendhal, plusieurs sortes de papiers vélins employés à des périodes différentes (de 1839 à 1842), qui portent un timbre identique permettant d’en identifier la provenance commune : « Chambellan, Papetier, 1 rue du Bouloi à Paris ». Dès lors, le recoupement des informations concernant le timbre sec, le papier, le scripteur (recours à un ou plusieurs copistes) et le texte nous a permis d’affirmer que Stendhal avait dicté soixante‑dix pages de son roman à Paris en mai 1839 au copiste Bonavie, le copiste de La Chartreuse de Parme, alors que l’on pensait jusqu’ici que ce roman avait été dicté à Rome à un secrétaire inconnu en octobre 183918.
Ainsi, les bases de données relationnelles permettent non seulement d’économiser la saisie redondante d’une même donnée, mais surtout d’optimiser le recoupement des données lors de requêtes multiples. Un système d’information correctement « pensé », répartissant dans un fichier précis les données concernant un seul et même type d’entité (l’instrument d’écriture, le type de papier, le scripteur…), permet d’envisager les requêtes les plus insolites. On a pu ainsi mener une enquête sur les habitudes d’écriture de Stendhal dans le manuscrit de Lamiel et s’apercevoir du rôle systématiquement réservé à tel instrument d’écriture : la mine de plomb par exemple, est uniquement utilisée pour corriger et annoter une version que Stendhal amplifie lors d’une nouvelle dictée.
Du fait de la complexité des relations possibles entre les supports et les campagnes d’écriture (un même feuillet peut porter plusieurs états génétiques, les brouillons d’une œuvre peuvent être répartis entre plusieurs volumes, une même version peut comporter l’intervention de plusieurs scripteurs sur les mêmes supports ou sur des supports différents, etc.), la création d’une base de données adaptée à la problématique des manuscrits d’auteurs nécessite les mêmes précautions, la même rigueur qu’une base utilisée au sein d’une entreprise dans des domaines considérés comme plus techniques. Cependant, il est évident que dans le cas de la littérature et plus généralement des sciences humaines, il convient de faire preuve de souplesse par rapport aux règles établies par les informaticiens. On ne peut cependant pas s’y soustraire totalement, car, indépendamment des habitudes de travail et de la part importante dévolue à l’interprétation dans les disciplines littéraires, la « machine » informatique ne peut fonctionner (pour le moment) que dans un cadre formel systématique, donc contraignant.
Le traitement des corpus : manuscrits de Montesquieu, Stendhal, Duchamp et Condorcet
Plusieurs projets de ces trois dernières années ont été menés en utilisant pleinement les fonctionnalités de la base pour émettre des hypothèses de classement inédites. Si on laisse de côté le cas de Condorcet, traité plus récemment, trois auteurs ont été abordés de façon systématique dans le cadre du programme « Archives de la création » qui a permis de tester et de mettre au point la base MUSE comme instrument de recherche : à savoir Montesquieu, Stendhal et Duchamp.
Sous le titre de L’Atelier de Montesquieu. Manuscrits inédits de La Brède19, Catherine Volpilhac‑Auger a publié les dossiers de « Rejets » de L’Esprit des lois conservés à la Bibliothèque municipale de Bordeaux sous la cote MS 2506. Une étude matérielle exhaustive de ces dossiers est venue étayer son travail de transcription et d’interprétation : vingt et un types de papiers ont pu être identifiés, regroupant plus de trois cents feuillets, tandis qu’une vingtaine d’occurrences demeurent « indéterminées ». À titre expérimental, un nouvel instrument de mesure a été testé sur ce corpus de vergés de fabrication manuelle : le perthomètre, qui permet d’évaluer avec une extrême précision la rugosité des papiers20. L’organisation physique des supports, souvent assemblés en cahiers in‑quarto et comportant de très nombreux ajouts épinglés, a donné lieu à une description détaillée, et nous avons procédé non seulement à un relevé de toutes les occurrences du MS 2506, mais à une comparaison extensive avec la correspondance et de nombreux manuscrits autographes et allographes (voir fig. 4), y compris bien sûr les six volumes du manuscrit de L’Esprit des lois conservé à la BnF. Les principaux résultats ont justement consisté à reconsidérer pour partie le statut des dossiers de La Brède, non seulement en relation à la genèse de cette œuvre mais dans le vaste chantier permanent entretenu par Montesquieu et ses secrétaires21.
La distinction entre des papiers d’origine locale employés à Bordeaux (filigranés « PERIGORD ») et les supports de travail parisiens, provenant d’Auvergne pour la plupart, a été riche d’enseignements. Coordonnée à une étude attentive des écritures, qui devrait à terme permettre aux spécialistes d’affiner l’identification des nombreux copistes employés par Montesquieu dans chacun de ses lieux de travail22, cette approche codicologique a donc fourni un matériau neuf aux éditeurs des Œuvres complètes en cours de préparation23. Enfin plusieurs recoupements internes ont facilité la mise en contexte de fragments jusqu’à présent mal situés et révélé des rapprochements inespérés au sein d’un corpus caractérisé par une grande mobilité : Montesquieu déplaçait des chapitres, les retranchait ici pour les ajouter là, insérait des ajouts, commentaires ou notes bibliographiques, prévoyait des développements ou réemplois ultérieurs. Autant de remaniements successifs dont l’analyse codicologique ne fait que souligner la complexité, tout en apportant d’utiles indices à l’interprétation.
Quant aux manuscrits de Stendhal, plusieurs enquêtes codicologiques ont été menées depuis 1997 sur diverses portions de l’impressionnant ensemble conservé à la Bibliothèque municipale de Grenoble. Nous n’en retiendrons ici que les résultats les plus parlants. Dans le cadre de sa thèse de doctorat sur la genèse de Lamiel24, Serge Linkès a su tirer parti des résultats inattendus issus de l’analyse codicologique des brouillons (719 ff. dont la rédaction s’étend d’avril 1839 à mars 1842). En effet, en contradiction avec la datation des diverses campagnes de rédaction telles qu’elles étaient perçues par la critique antérieurement, ses travaux ont établi une chronologie fort différente des premières phases de la genèse du roman inachevé, en se fondant notamment sur les recoupements entre la provenance italienne ou française des supports et les interventions successives des copistes romains, de l’auteur lui‑même lors de ses séjours à Civita‑Vecchia et d’un copiste parisien, Bonavie. Une fois encore, c’est bien évidemment le croisement entre l’identification matérielle précise de tous les feuillets concernés, les informations graphiques relevées par S. Linkès et son examen critique des phases rédactionnelles qui a donné toute leur force démonstrative aux hypothèses dégagées grâce l’emploi de la base MUSE. À terme, d’autres relevés déjà effectués ou encore à faire permettront sans doute d’étayer diverses recherches génétiques et critiques25. Par ailleurs, le corpus des manuscrits stendhaliens pose au codicologue un défi particulièrement aigu, puisqu’il comporte comme nous l’avons signalé de nombreux vélins non filigranés fort difficiles à distinguer à l’œil nu. Une enquête approfondie sur ces supports à l’aide d’instruments de mesure jusqu’à présent rarement accessibles hors des laboratoires serait souhaitable si l’on veut parvenir à une description plus complète des papiers employés par Stendhal26.
Le cas des écrits de Marcel Duchamp est particulièrement délicat puisque ces fragments ont été rédigés et copiés à diverses reprises tout au long de la carrière mouvementée de l’artiste, sur des supports les plus divers : de la « pelure d’oignon » américaine aux vergés mécaniques filigranés à l’effigie de Madame de Sévigné (voir fig. 5), des cartons d’invitation réutilisés au papier à lettres le plus raffiné, de marque « Crane », en passant par les feuillets à en‑tête d’hôtels, de restaurants ou de paquebots, les cahiers d’écoliers, pages de registres commerciaux et autres marges d’annuaires téléphoniques. De fait, le caractère délibérément discontinu de ces notes est souligné par les déchirures et découpages systématiques, l’usage de feuilles entières demeurant exceptionnel. La fabrication industrielle du papier rend par ailleurs moins efficaces les critères distinctifs détectables à l’œil nu et mesurables sans instruments sophistiqués. Néanmoins notre protocole descriptif s’est avéré utile en vue d’apporter à la critique de nouveaux arguments : tantôt l’identification des supports a permis de préciser, de confirmer ou d’infirmer une datation relative par comparaison avec des lettres et écrits datés, tantôt on a pu proposer des rapprochements entre plusieurs fragments, parfois conservés en des lieux différents, allant même jusqu’à reconstituer des feuilles complètes à partir de fragments aujourd’hui séparés mais dont la déchirure s’avérait jointive. Les recoupements avec les instruments d’écriture ont parfois permis de dégager des séries. En dépit des nombreuses énigmes qui subsistent, la perception de ce corpus hétéroclite offre désormais plus de prise au classement (qu’il soit d’ordre génétique, chronologique voire thématique)27. Or de tels rapprochements ont été rendus « visibles » par une utilisation systématique des croisements de données au sein de la base de travail constituée à partir des collections de Paris, New York, Yale et Philadelphie.
Si les corpus du XVIIIe siècle se prêtent plus aisément au traitement, ce n’est pas en raison des fonctions de la base MUSE : dans l’état actuel de nos moyens d’observation, les caractéristiques de la fabrication manuelle (dominée par le vergé) offrent des indices plus nombreux et plus facilement perceptibles que celles de la fabrication mécanique (où le vélin tend à prédominer). En outre, les connaissances en histoire du papier, utiles notamment à la datation, sont bien mieux répertoriées pour cette période que ne le sont les informations commerciales sur les produits de l’ère industrielle. Alors que la base elle‑même est conçue pour traiter également toute forme de support, la part de l’observation et celle des compléments d’information d’ordre historique s’avèrent pour l’instant moins riches, et beaucoup plus coûteuses à enrichir, dès que l’on aborde la seconde moitié du XIXe et le XXe siècle. Ainsi l’application du protocole descriptif de MUSE aux manuscrits du Tableau historique des progrès de l’esprit humain de Condorcet s’est avérée, toutes proportions gardées, presque aussi fructueuse que l’étude des papiers de Diderot ou de Montesquieu, quoique l’enquête porte sur des documents moins complets.
Comme l’avait établi la tradition critique, les manuscrits du Tableau historique conservés pour l’essentiel à la Bibliothèque de l’Institut se répartissent en trois périodes de rédaction bien distinctes : le projet initial de 1772, un nouveau projet datant de la fin des années 1780, et une ultime mouture inachevée, rédigée pendant les dernières années de Condorcet, en 1793 et 179428. En effet, les supports de ces trois périodes sont suffisamment différents, notamment quant à leur provenance géographique, pour confirmer une telle répartition et permettre de dater presque « automatiquement », grâce à la chronologie matérielle établie par MUSE, un certain nombre de « textes isolés » jusqu’à présent mal situés. Bien que le corpus des trois projets, assez lacunaire, se caractérise par une extrême hétérogénéité des supports (on rencontre jusqu’à six types de papiers différents pour un texte suivi de neuf feuillets !), de nombreux recoupements s’imposent, indices des campagnes d’écriture successives (par exemple dans le cas du Prospectus). En dépit d’une correspondance quasi inutilisable car elle s’avère fort peu datée, on parvient, à l’aide des brouillons de discours politiques des années révolutionnaires ou par comparaison avec divers textes datés par leur publication, à resserrer la fourchette de datation de plusieurs séquences de feuillets. En se fondant sur une durée d’utilisation limitée, attestée par plusieurs occurrences, il devient possible de révoquer en doute une hypothèse concernant la réutilisation a posteriori d’un plan qui aurait été composé avant 1793. Enfin la composition complexe de telle liasse cousue en cahier, qui comporte divers ajouts par collage et où la main de l’auteur alterne avec celle du copiste, semble s’élucider lorsque l’on distingue les différents types de supports employés et que l’on examine leur insertion dans la couture. Quant à l’attribution aux scripteurs, l’analyse des papiers a d’emblée permis d’éliminer du corpus plusieurs copies datant du xixe siècle ; à terme, une étude plus large devrait contribuer à l’identification des copistes employés par Condorcet, dont les activités sont encore mal répertoriées. Si la vision qu’offre le corpus du Tableau analysé par la base MUSE est moins panoramique que celle fournie par l’examen codicologique du dossier MS 2506 sur « l’atelier » de Montesquieu, notre enquête n’en donne pas moins des aperçus éclairants sur la façon de travailler de Condorcet29.
Autres corpus représentés et limites actuelles de l’application
Dans l’état actuel, la base comporte plus de huit cent cinquante entrées définissant des types de papiers, et près de trois mille entrées d’occurrences concernant une séquence de feuillets du même type (soit de un à plusieurs centaines de feuillets par entrée, dans le cas de volumes entièrement homogènes), provenant de plus de cinq cents volumes. Y sont représentés quatre‑vingts auteurs de la fin du xviie siècle au milieu du XXe et plusieurs centaines d’œuvres : de la correspondance de Bossuet à celle de Chateaubriand en passant par les lettres de Diderot à Sophie Volland, des brouillons de L’Esprit des Lois à ceux de la Tentation de saint Antoine ou de la Légende des siècles, des cahiers reliés par Stendhal pour la Vie de Henry Brulard ou Lamiel aux cahiers d’écolier de Roussel ou de Malraux, des notes de Renan pour la Vie de Jésus aux feuillets de Gide pour La Porte étroite.
Si le papier de fabrication manuelle est largement représenté dans la base, avec d’importants corpus de manuscrits du XVIIIe siècle (en particulier Diderot, Montesquieu et Condorcet), les supports de fabrication industrielle sont également présents, et appelés à une augmentation sensible (les corpus partiels de Balzac, Zola, Duchamp et Valéry, traités séparément, seront prochainement intégrés dans la base). Lors de l’industrialisation lente et progressive des moulins en France entre 1820 et 1850, de nombreux papiers vélins utilisés pour l’écriture ne portaient pas de filigranes, ce qui rend la distinction des types de papier beaucoup plus délicate, même s’ils sont parfois pourvus d’un timbre sec qui permet de les différencier30. Les manuscrits de Balzac et ceux de Stendhal comportent une proportion importante de ce genre de supports, dont l’inventaire systématique impliquerait un recours aux instruments de mesure afin de déterminer l’appartenance à l’un ou l’autre type de fragments dont les dimensions ne sont pas complètes. En attendant une étude complémentaire, des relevés partiels incluant les types de papier non filigranés les plus aisés à reconnaître figurent déjà dans la base. Ainsi MUSE se distingue nettement des bases de données prenant le relais des répertoires de filigranes imprimés.
Par un autre aspect, MUSE illustre une conception de la codicologie qui ne s’en tient pas à l’identification des filigranes, mais entreprend une description approfondie de la constitution matérielle, souvent complexe, des recueils manuscrits : le fichier « Supports » vient compléter l’identification des types (fichier « Papier ») et la liste des « Occurrences », en indiquant pour chaque feuillet, bifeuillet ou séquence de feuillets le pliage, ainsi que l’éventuelle intervention d’assemblages ou de collages (coutures, ajouts fixés par des épingles, agrafes ou point de cire à cacheter), voire les altérations (déchirures, talons attestant l’ablation de feuillets) et restaurations subies. Ainsi les occurrences ne constituent pas un simple outil de datation ou de localisation, mais nous renseignent sur les modalités d’utilisation du support, qui peuvent varier pour un même type de papier selon l’utilisateur et sa fonction (auteur, secrétaire ou copiste), la nature du document (plan, brouillon, notes de lecture, mise au net, etc.) et les circonstances de la rédaction31. Seul un relevé complet et attentif des occurrences permet ainsi de fournir à l’interprétation un réseau d’indices concernant non seulement la nature des supports utilisés mais la façon de les utiliser.
Si MUSE peut être considérée comme une avancée non négligeable dans le domaine du traitement informatique des données littéraires, il faut signaler que cette application, dans son état actuel, connaît certaines limites que nous nous évertuons à corriger. L’un des points qui méritent toute notre attention concerne les mises à jour partielles de la base qui suivent les campagnes de saisie effectuées in situ. Pour le moment, les données saisies sur un ordinateur portable doivent être transférées sur la base principale installée sur un poste fixe de l’ITEM. Dès lors, on imagine les risques qu’engendrent de telles manipulations : multiplication des bases avec des versions différentes, écrasement du mauvais fichier lors du transfert… Une évidence s’impose, il ne devrait exister qu’une seule version de MUSE à laquelle les utilisateurs fixes ou itinérants se connecteraient. Il paraît donc nécessaire d’envisager, dès que possible, de mettre cette base de travail en réseau. Cependant, la mise en réseau de MUSE doit être conçue d’un point de vue à la fois interne et externe : le chercheur doit pouvoir non seulement travailler sur MUSE de n’importe quel point de l’ITEM et des locaux qui l’abritent (Intranet) mais aussi de n’importe quel point de France et du monde (bibliothèques et institutions de conservation) puisque MUSE ne se limite pas aux seuls manuscrits français (Internet).
Fig. 6 : Évolution de la Base MUSE ‑ Mise en réseau et élaboration de l'interface de consultation

Cette perspective ne pose pas de réel problème pour l’Intranet, mais il en va tout autrement pour l’Internet. En effet, cela implique que chaque institution de conservation possède un accès réseau de très haut débit, et surtout qu’elle autorise le chercheur à se connecter à ce réseau. Du point de vue du logiciel, il n’y a que peu de modifications à effectuer pour permettre une utilisation de MUSE, la base de travail, sur un réseau interne ou externe. Les principes restent les mêmes que la base soit autonome ou « multi‑utilisateurs », d’autant plus que l’utilisation de cette base sera limitée aux chercheurs et soumise à autorisation. Il n’en est pas de même si l’on envisage de permettre la consultation de MUSE sur Internet en tant que base de référence.
Deux aspects essentiels exigeraient pour ce faire une amélioration. D’une part, il conviendrait de séparer la base « de consultation » accessible des diverses bases « de travail » utilisées pour décrire un corpus et l’analyser – qui contiennent notamment un certain nombre de types « indéterminés », c’est‑à‑dire d’occurrences incomplètes en attente d’attribution à un type définitif. De telles bases ne sauraient servir de référence, car elles risqueraient d’induire en erreur les utilisateurs et d’alourdir inutilement les recherches : elles doivent être considérées comme des outils de travail, partiellement personnalisables, tant que dure le « chantier » d’investigation sur un corpus. Quand une étude est considérée comme aboutie, ou interrompue, l’ensemble des données que l’on estimera définitives (à l’exclusion des types indéterminés) devrait être extrait et communiqué à une base unique, contrôlée par un gestionnaire, seule susceptible de faire référence et seule accessible publiquement pour la consultation sur Internet.
D’autre part, se pose le problème de l’illustration de la base par l’insertion d’images numérisées reproduisant les filigranes (et le cas échéant les timbres secs), soit à partir de bêtaradiographies scannées et traitées – comme ce fut initialement le cas pour la base Profil –, soit directement à partir de photographies numériques prises sur les originaux. Après l’interruption définitive de l’utilisation de la source bêtaradiographique du service de reprographie de la BnF en 1994, nous avons cessé d’alimenter régulièrement notre base (Profil, puis MUSE) en images. Quelques corpus ont été reproduits depuis lors par photographie numérique (filigranes de manuscrits de Balzac, de Condorcet32) mais nous n’avons pas encore procédé à leur intégration à la base. La présence des images est évidemment cruciale, aux côtés de la description des types de papier, afin de faciliter la comparaison des filigranes rencontrés à un « modèle » virtuel aussi complet que possible. Par ailleurs elle nécessite un volume de mémoire important et alourdit notamment la consultation sur ordinateur portable. Diverses solutions doivent donc être envisagées pour résoudre ces difficultés tant au niveau des prises de vues (reprographie à la BnF, autorisation de prises de vues dans d’autres bibliothèques) que du traitement des images numériques.
S’il reste beaucoup à faire pour offrir aux chercheurs intéressés un accès autonome à l’utilisation de la base de recherche, nous pensons que la consultation de la base commune de référence sur Internet peut être envisagée dans des délais raisonnables, sous réserve de mises à jour ultérieures pour compléter l’acquisition des images encore manquantes. Telle quelle, et partant du principe que la base s’accroîtra régulièrement des données collectées au cours de nouvelles enquêtes manuscriptologiques, MUSE offre déjà une source d’information non négligeable sur les supports et les techniques d’écriture en usage à la période moderne, spécifiquement dans le champ littéraire. Les données qu’elle rassemble pour les livrer aux interrogations croisées de diverses disciplines contribuent à combler un manque de ressources particulièrement sensible en France en matière d’histoire du papier. C’est pourquoi cet instrument de travail a également été conçu dans une perspective pédagogique, la codicologie des documents modernes n’apparaissant guère dans les programmes universitaires destinés aux littéraires ou aux historiens.
Quant aux applications de MUSE à la recherche, on pourrait presque parler d’herméneutique matérielle puisque l’analyse matérielle participe de plein droit à l’examen critique de tous les indices, signes et symboles qui composent le manuscrit. La démarche génétique consiste bien dans ce cas à réunir et à confronter toutes les traces matérielles des processus de la création littéraire afin de les mettre en relation les unes avec les autres, en un faisceau de données structurées, susceptible d’orienter l’interprétation critique.
MUSE n’est donc pas une simple base de données codicologique, mais un véritable auxiliaire de recherche génétique permettant d’élaborer des hypothèses à partir de la mise en relation d’un grand nombre d’éléments matériels et descriptifs. Les hypothèses produites à l’aide de MUSE sont doubles :
codicologiques d’abord, puisqu’elles permettent d’établir une typologie rigoureuse des données matérielles (types de papier, types d’instrument d’écriture…) à partir d’un inventaire méthodique ;
génétiques ensuite, puisqu’elles autorisent une analyse systématique et affinée des données descriptives portant sur les avant‑textes, analyse étayée et confirmée par les résultats de l’enquête codicologique.
Un outil tel que MUSE, moyennant une adaptation nécessaire au travail en réseau, permettra à plus ou moins longue échéance d’établir ou de rétablir la genèse d’œuvres littéraires sur des fondements codicologiques et critiques rigoureux, notamment grâce à la comparaison de plusieurs corpus contemporains. On peut supposer que le rapprochement de données collectées à partir de manuscrits d’auteurs différents devrait permettre d’enrichir l’étude génétique de chacun d’eux. Ainsi, la reconnaissance de types de papier identiques sous des plumes différentes contribuera à dater des liasses et à reclasser des brouillons. À un stade plus avancé, on peut supposer qu’il sera possible de mener une étude synchronique des processus d’écriture. Le fait que MUSE soit adaptée à la saisie des données codicologiques et génétiques de corpus du XVIIe au XXIe siècle rend envisageable d’entreprendre le même type d’enquête d’un point de vue diachronique et d’esquisser une histoire de l’évolution des processus d’écriture et des opérations génétiques, histoire encore mal connue et dont les brouillons d’écrivains constituent les témoins matériels les plus précieux.
1 Voir le remarquable essai de D. Ferrer, « Le matériel et le virtuel : du paradigme indiciaire à la logique des mondes possibles », Pourquoi la critique génétique ? Méthodes, théories, sous la direction de M. Contat et D. Ferrer, CNRS Éditions, 2001, p. 11‑30 et nos propositions en ce sens : C. Bustarret, « Les manuscrits littéraires modernes et leurs supports », Histoire de l’écriture. De l’idéogramme au multimédia, sous la direction d’A.‑M. Christin, Flammarion, 2001, p. 332‑339.
2 Standard descriptif pour manuscrits modernes, CNRS, ITEM, 1985, 23 p. (existe en traductions anglaise et allemande).
3 Colloque international Papier et filigranes : documentation, images, informatisation, organisé par l’ITEM (CNRS) et le département des Arts graphiques du musée du Louvre, novembre 1993, Bibliothèque nationale de France.
4 Voir C. Bustarret, « L’histoire du papier appliquée à l’étude des manuscrits modernes : la base de données Profil », Livre des Congrès IPH,vol. 10, 1994, p. 39‑43.
5 Intégration encore rare dans ce domaine au début des années quatre‑vingt‑dix, obtenue grâce à la contribution de Daniel Charraut et Philippe Jourdain du Laboratoire d’optique de l’université de Besançon pour le traitement des images.
6 Par « type de papier », on entend le modèle de toutes les feuilles de papier produites par la même forme (ou paire de formes quasi identiques) employée dans la fabrication manuelle ; pour la production industrielle, la notion perd de sa pertinence au niveau technique puisque des centaines de feuilles sont produites simultanément, et découpées après séchage : on se réfère alors au produit commercial de format, couleur, texture, grammage et éventuellement filigrane semblable.
7 Voir C. Bustarret et B. de la Passardière, « Profil, an iconographic database for modern watermarked papers », Computer and the Humanities, 36, 2002, p. 143‑169.
8 Nos critères correspondent, à quelques détails près, aux champs prioritaires marqués d’un astérisque dans la Norme internationale d’enregistrement des papiers filigranés de l’Association internationale des Historiens du Papier, IPH, 1996.
9 Projet « Répertoire automatique des filigranes modernes » financé par le CNRS dans le cadre d’un GDR (puis GIS) avec la Bibliothèque nationale (1988‑1994).Toutes ces données ont été intégrées dans la nouvelle base, y compris les images numérisées et traitées.
10 Signalons notamment les sites « A Digital Catalogue of Watermarks and Type Ornaments Used by W. Stansby in the Printing of The Workes of Beniamin Jonson (London, 1616) » (http://jefferson.village.virginia.edu/gants) datant de 1996, « Archive of Papers and Watermarks in Greek manuscripts », mis à jour jusqu’en 1999 (http://abacus.bates.edu :80/Faculty/wmarchive), et « The Thomas L. Gravell Watermark Archive », mis à jour jusqu’en 2001 (http://ada.cath.vt.edu/591/DBs/Gravell/default.html).
11 Signalons dans le domaine des manuscrits anciens le site de l’Institut de recherche et d’histoire des textes du CNRS qui propose une version allégée de la base de données MEDIUM. De même, la diffusion sur Internet de la base de données INITIALE permet, selon un accès par cote, de voir des images de manuscrits enluminés des bibliothèques municipales de Vendôme et d’Orléans, principe que l’on retrouve sur le site « Liber Floridus » qui offre « la consultation à un large public de l’ensemble des enluminures des manuscrits médiévaux conservés dans les bibliothèques de l’enseignement supérieur » (http://liberfloridus.cines.fr/). Le Comité international de paléographie latine propose également une base de données accessible par Internet : le Catalogue des manuscrits en écriture latine portant des indications de date, de lieu ou de copiste, qui n’est en fait que la reproduction électronique du Catalogue publié sous la direction de C. Samaran et R. Marichal (Paris, 1961‑1985 ; 7 x 2 vol.).
12 Et parallèlement le programme de numérisation du patrimoine culturel mené par le ministère de la Culture et de la Communication.
13 Ainsi lors d’une enquête sur les supports employés par Flaubert et Bouilhet pour la rédaction de Pierrot au sérail, la consultation de la base a permis un recoupement avec certains brouillons de Madame Bovary : voir M. C. Olds, Au pays des perroquets. Féerie théâtrale et narration chez Flaubert, Amsterdam, Atlanta, Rodopi, coll. « Faux‑titre », 2001, Appendice, p. 181‑188 : « Résultats de l’analyse codicologique menée par C. Bustarret ».
14 Voir C. Ginzburg, Mythes, emblèmes, traces, Paris, Flammarion, 1989 et D. Ferrer, art. cit.
15 Voir C. Bustarret, « Paper Evidence and the Interpretation of the Creative Process in Modern Literary Manuscripts », L’Esprit créateur, éd. R. Pickering, vol. XLI, 2, été 2001, p. 16‑28, ainsi que « Les papiers de Montesquieu : une approche codicologique du fonds de La Brède », Revue Montesquieu, 3, 1999, p. 179‑187.
16 Le meilleur modèle d’une telle démarche, appliquée à l’œuvre graphique de Turner, nous est offert par le remarquable ouvrage de Peter Bower : Turner’s Papers, A Study in the Manufacture, Selection and Use of his Drawing Papers (2 vol. 1787‑1820, 1820‑1851), Londres, Tate Gallery, 1990 et 1999.
17 Si l’on applique l’intégrité référentielle, la base vous empêche d’ajouter des enregistrements à un fichier lié lorsque le fichier source ne contient pas d’enregistrement associé, ou de procéder à la modification de valeurs dans le fichier source qui entraînerait des enregistrements orphelins dans un fichier lié, et de supprimer des enregistrements dans le fichier source lorsque le fichier lié contient des enregistrements correspondants.
18 Sur ce point voir S. Linkès, « Le manuscrit de Lamiel : la fin d’une énigme ? » dans Le Dernier Stendhal 1837‑1842, Paris, Eurédit, 2000.
19 C. Volpilhac‑Auger, avec la collaboration de C. Bustarret, L’Atelier de Montesquieu, Manuscrits inédits de La Brède, Naples, Liguori Editore, Oxford, Voltaire Foundation, 2001.
20 Les relevés effectués par L. Rauzier ont permis d’établir des moyennes pertinentes, toutefois l’irrégularité du grain dû à la fabrication manuelle tendait à dépasser les capacités discriminatoires de l’appareil. Il est apparu qu’une utilisation systématique sur de tels corpus exigerait un protocole de mesure plus adapté.
21 Voir infra l’article de C. Volpilhac‑Auger, « Montesquieu : le chantier génétique ».
22 G. Benrekassa, Les Manuscrits de Montesquieu : secrétaires, écritures, datations, Cahiers Montesquieu,8, Naples, Liguori Editore, Oxford, Voltaire Foundation, à paraître en 2003. Un projet en cours dit « Numérisation et valorisation des corpus » traitant de manière privilégiée des manuscrits de Montesquieu associe le laboratoire « Reconnaissance de formes et Vision » de l’INSA (Lyon I) et l’UMR CNRS 5037 (ENS de Lettres et sciences humaines, C. Volpilhac‑Auger). Il s’agit d’un projet de numérisation adaptée à la reconnaissance des formes, par recours aux méthodes fractales, à l’analyse des textures (pour l’identification automatique des scripteurs et la datation), et à l’étude de la structuration des documents. L’analyse des papiers est toujours conçue comme le complément indispensable de ces études.
23 Montesquieu, Œuvres complètes, 22 vol., Oxford, Voltaire Foundation. Le manuscrit de L’Esprit des lois cité plus haut sera intégralement publié aux tomes III et IV de cette édition (par les soins de G. Benrekassa), les manuscrits « de La Brède » devant être repris dans le tome VII, qui présentera le « dossier de L’Esprit des lois ». Les premiers volumes parus (t. II, XIII et XVIII), et le tome VIII (sous presse) n’ont pu tenir compte des apports de l’analyse codicologique, sinon de manière très partielle ; les suivants en tireront systématiquement parti.
24 S. Linkès, Genèse de Lamiel, le chaînon manquant, thèse de doctorat sous la direction de Mme B. Didier, université Paris VIII, 21 décembre 2000 (à paraître S. Linkès, Stendhal, Genèse de « Lamiel », le chaînon manquant, texte remanié et augmenté de la thèse de doctorat, Paris, éd. Honoré Champion, coll. « Textes de littérature moderne et contemporaine » dirigée par A. Montandon, 2004).
25 Par exemple l’étude menée par D. Ferrer, J.‑J. Labia et M.‑I. Mena‑Barreto sur Le Rose et le Vert.
26 Un projet de l’équipe « Techniques et pratiques de l’écrit » de l’ITEM, coordonné avec l’équipe de Physique du Papier de l’École de Papeterie de Grenoble (EFPG) et la bibliothèque municipale et universitaire, interrompu en 2000 faute de financement, a tracé la voie à suivre dans cette direction.
27 Voir C. Bustarret et H. Obalk, « Pour une codicologie des manuscrits de Marcel Duchamp », Genèses, sous la direction de P.‑M. de Biasi (à paraître en 2003) ainsi que le Catalogue raisonné des écrits de M. Duchamp que prépare également H. Obalk. À défaut de reproduction des manuscrits de M. Duchamp, nous donnons ici une image numérisée d’un filigrane presque identique, du même fabricant, reproduit par bêtaradiographie dans un manuscrit de La Recherche du temps perdu.
28 Voir P. Crépel, « Esquisse d’une histoire du Tableau historique », MEFRIM n° 108, 1996‑2, p. 469‑504 ; N. Rieucau, « La neige avait‑elle recouvert le volcan ? L’écriture par Condorcet du Tableau historique des progrès de l’esprit humain », Genesis n° 22, à paraître fin 2003, et « Condorcet’s social mathematic : a few tables », Social Choice and Welfare, à paraître en 2003.
29 Voir Condorcet, Tableau historique des progrès de l’esprit humain, édition critique, Paris, INED, à paraître fin 2003.
30 Voir à ce propos C. Bustarret, « Interroger “l’existence matérielle de l’œuvre” : une enquête sur les papiers de Balzac », Actes du colloque « Lire Balzac en l’an 2000 : bilans et perspectives», L’Année balzacienne, 1999 (II), p. 503‑527.
31 On comparera par exemple les cas de figure fort éloignés que constituent les corpus de R. Roussel et d’É. Zola : C. Bustarret et A.‑M. Basset, « Les Cahiers d’Impressions d’Afrique : l’apport de la codicologie à l’étude génétique », Genesis, n° 5, printemps 1994, p. 153‑166 et C. Bustarret, « Enquête sur les papiers dans les dossiers préparatoires : Zola ou le degré zéro du support ? », Zola : genèse de l’œuvre, Paris, CNRS Éditions, 2002, p. 263‑279.
32 Grâce à l’aimable autorisation de la Bibliothèque de l’Institut de France.